How to Write to Files in Python: A Beginner’s Guide
Our take
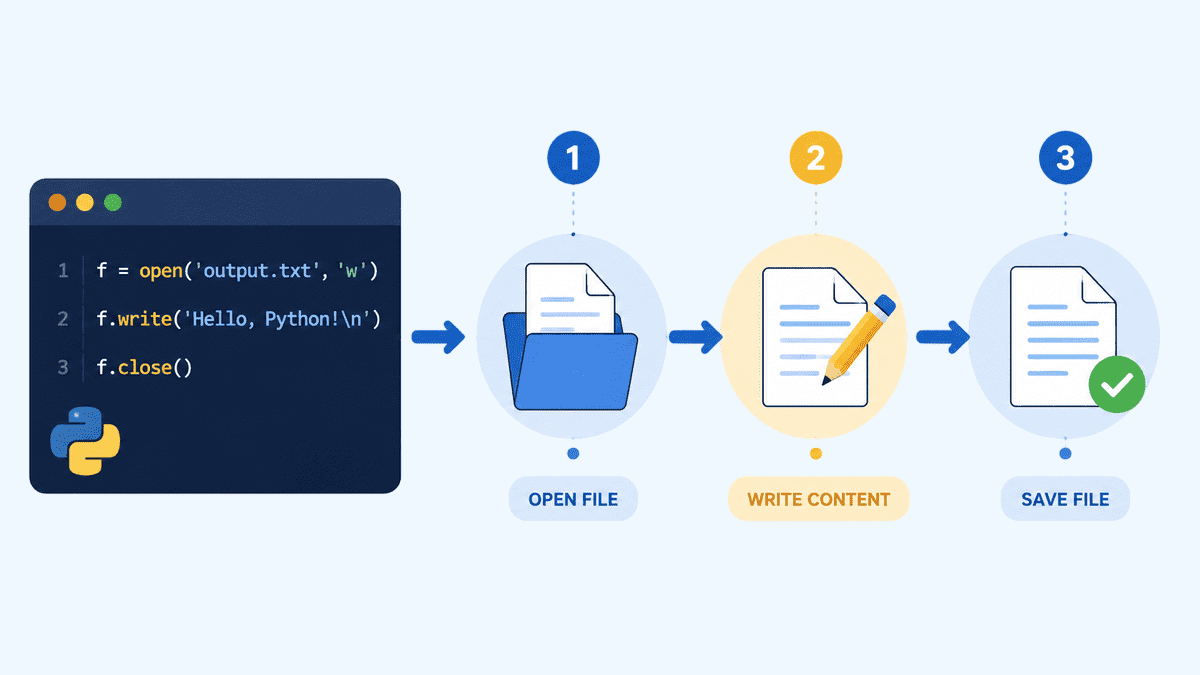
The practical skill of writing to files in Python is more than a coding chore—it is the backbone of data pipelines that drive modern analytics. In the beginner’s guide “How to Write to Files in Python,” the authors walk readers through the essentials of handling text, CSV, and JSON files with native tools, a foundational step for any data professional who wants to move beyond spreadsheets into automated, reproducible workflows. This article dovetails nicely with our recent exploration of time‑series techniques in “7 Steps to Mastering Time Series Analysis with Python”(/post/7-steps-to-mastering-time-series-analysis-with-python-cmq60aoya01op12xwqq7n2roy) and the broader shift toward autonomous data operations highlighted in “What the Agentic Era Means for Data Science”(/post/what-the-agentic-era-means-for-data-science-cmq60ajkh01od12xwypfys9q8). Together, they underscore a common theme: the transition from manual, error‑prone data handling to streamlined, AI‑enhanced processes.
Why does mastering file I/O matter? In many real‑world scenarios, data arrives in bulk from APIs, sensors, or legacy systems. The ability to programmatically write, append, and serialize that data into human‑readable text, CSV spreadsheets, or JSON documents is the first step toward building reliable ingestion pipelines. Without this skill, analysts risk repeating manual export steps, which not only slows productivity but also introduces opportunities for data loss or inconsistency. By leveraging Python’s built‑in `open()`, `csv`, and `json` modules, developers can keep their code lightweight and maintainable—an advantage when scaling to larger datasets or integrating with cloud storage services. Moreover, the article’s emphasis on “out‑of‑the‑box” tools signals that sophisticated automation does not require exotic libraries; rather, it demands disciplined use of the language’s core capabilities. This approach aligns with our human‑centered philosophy: empower users to solve complex problems without drowning them in tooling overhead.
The broader significance extends into the realm of reproducibility and collaboration. When analysts share scripts that read from and write to standardized file formats, peers can run the same code on their own machines and achieve identical results. This reproducibility is essential for auditability in regulated industries and for fostering trust in data‑driven decisions. Additionally, the guide’s coverage of appending data—an operation that many novices find tricky—enables incremental data collection without overwriting historical records. In practice, this means that monitoring dashboards, error logs, and incremental model updates can all be managed through simple file operations, reducing the need for complex database setups in early prototypes or small teams.
Looking ahead, the skills outlined in this beginner’s guide will become even more valuable as organizations adopt hybrid workflows that combine on‑premise data lakes with cloud‑native services. Python’s native file handling remains a versatile bridge between local development environments and distributed storage. As AI agents begin to orchestrate data pipelines autonomously, the foundational knowledge of file I/O will allow these agents to trust the data sources they interact with, ensuring that automated transformations are grounded in reliable input and output. In a future where data scientists and AI assistants collaborate seamlessly, the ability to write, append, and serialize data confidently will remain a cornerstone of effective, scalable analytics.
In closing, the article reminds us that the simplest tools can unlock the most powerful workflows. By mastering file writing in Python, data practitioners lay the groundwork for more ambitious projects—whether that means building robust time‑series models, deploying AI agents that manage data life cycles, or crafting dashboards that evolve with real‑time insights. The next question for our community is how we can further integrate these basic operations into higher‑level frameworks that automate error handling, schema validation, and version control, thereby turning everyday file writes into fully auditable, production‑ready components.
Read on the original site
Open the publisher's page for the full experience